数据入湖
点击左侧菜单栏 数据入湖 项,查看当前工作空间下已创建的入湖任务列表。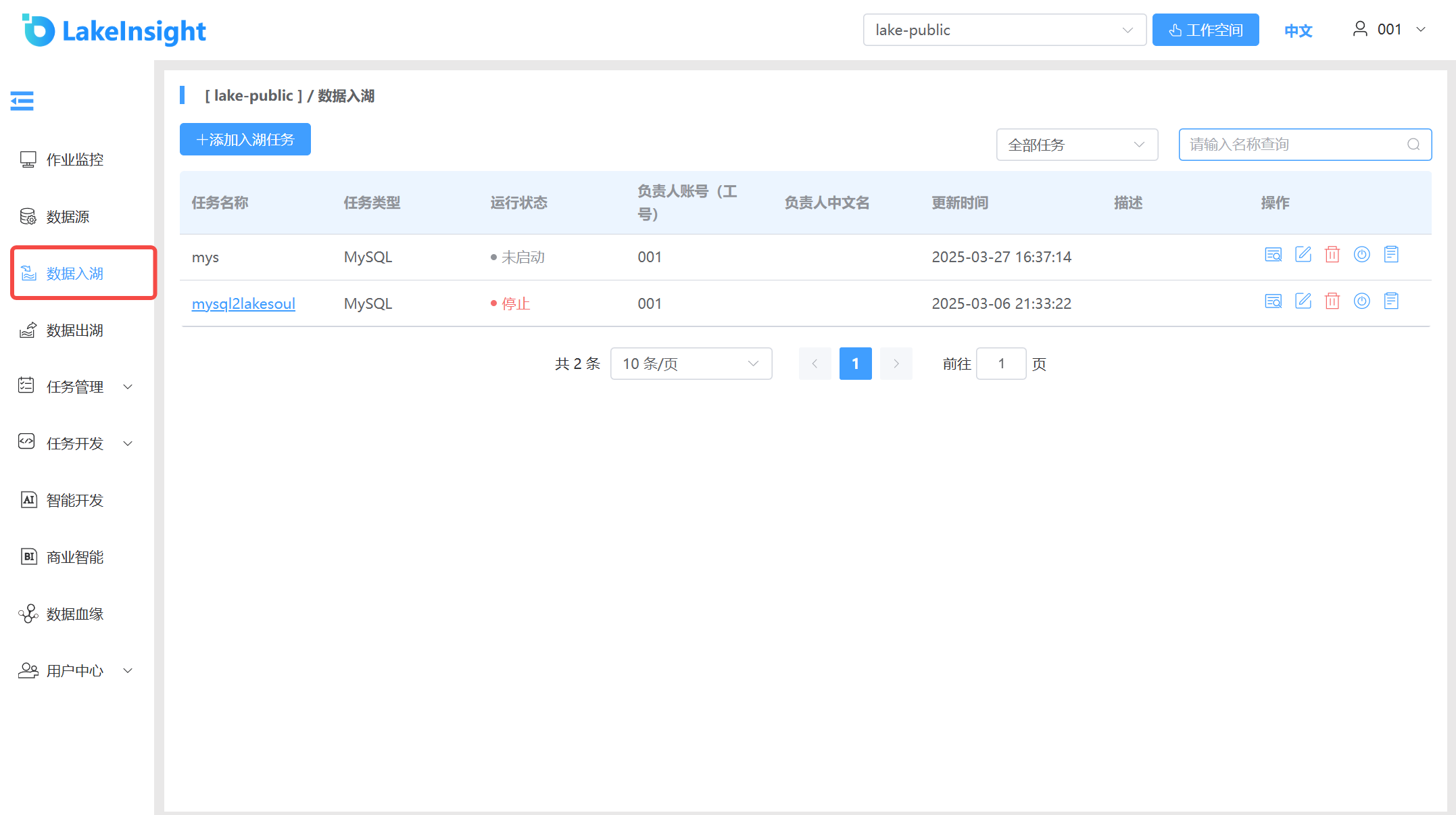
创建入湖任务
点击 添加入湖任务 按钮,从上到下按表单框依次填写资源信息,分别输入入湖任务名称、选择数据源(不同数据源会显示不同的配置表单),以及其他所需的资源信息。点击创建即可新增一个入湖任务。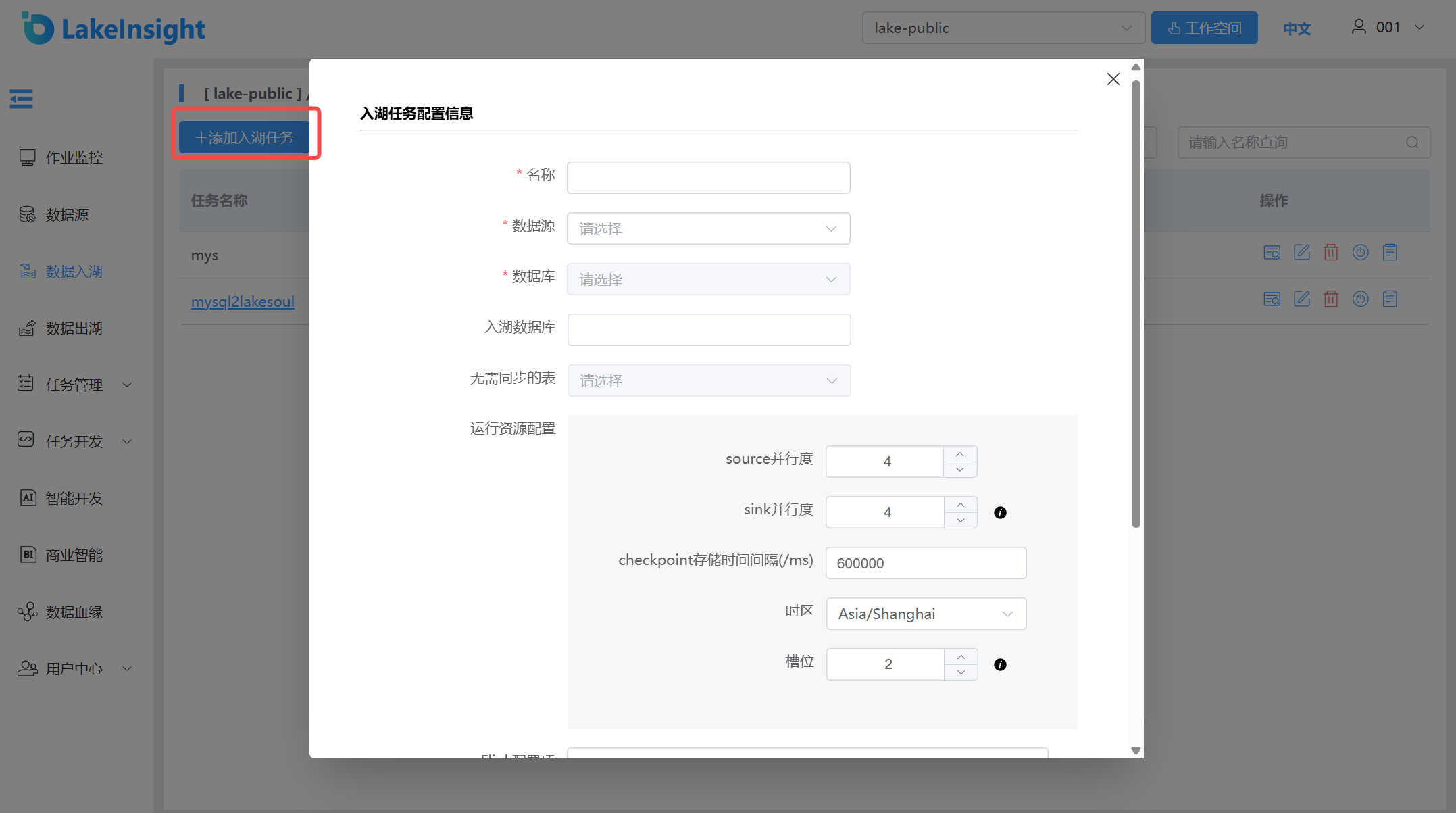
任务参数说明:
PostgreSQL数据入湖说明:
版本限制目前仅支持同步9.6、10、11、12、13、14、15和16版本的PostgreSQL的数据。您可以通过执行
select version()命令来查看PostgreSQL的版本。开启逻辑解码数据同步账号需要拥有REPLICATION和LOGIN权限,以及需要同步表的SELECT权限。
请确保wal_level的值为logical,修改postgresql.conf并重启数据库。
请确保需要同步的表的replica identity的级别为FULL。replica identity是PostgreSQL特有的表级设置,它决定了逻辑解码插件在发生(INSERT)和更新(UPDATE)事件时,是否包含涉及的表列的旧值。REPLICA IDENTITY取值含义详情请参见REPLICA IDENTITY。
需要确保max_wal_senders和max_replication_slots的参数值均大于当前数据库复制槽已使用数与Flink作业所需要的slot数量。
确保账户系统权限为SUPERUSER或者同时拥有LOGIN和REPLICATION权限,并且具有订阅表的SELECT权限用于全量数据查询。
您可以通过以下SQL代码查看并修改相应参数。
-- 查看replica identity。
SELECT CASE relreplident
WHEN 'd' THEN 'default'
WHEN 'n' THEN 'nothing'
WHEN 'f' THEN 'full'
WHEN 'i' THEN 'index'
END AS replica_identity
FROM pg_class
WHERE oid = 'mytablename'::regclass;
-- 修改replica identity。
ALTER TABLE mytablename REPLICA IDENTITY FULL;
创建具有同步权限的账号
CREATE ROLE <replication_user> REPLICATION LOGIN;
GRANT SELECT ON <table_name> TO <name>;数据同步插件
PostgreSQL 10及以上的版本,默认已经安装了同步插件pgoutput。而对于其它版本或需要安装其它同步插件的,可以参见安装逻辑同步插件。
如果您使用pgoutput作为同步工具,则请确保该账号是需要同步表的Owner。您可以参照如下步骤,确保同步账号是需要同步表的Owner。
-- 1.创建一个同步组。
CREATE ROLE <replication_group>;
-- 2.将原来表的owner加入到同步组中。
GRANT REPLICATION_GROUP TO <original_owner>;
-- 3.将同步账号加入到同步组中。
GRANT REPLICATION_GROUP TO <replication_user>;
-- 4.将相关的权限转给同步组。
ALTER TABLE <table_name> OWNER TO REPLICATION_GROUP;
说明:
此时同步账号只是单表的所有者,因此请在WITH参数内设置debezium.publication.autocreate.mode值为filtered。如果您觉得为每张表设置相关权限过于繁琐,则可以直接赋予同步账号pg_monitor权限。
GRANT pg_monitor TO <replication_user>;
Kafka数据入湖参数说明:
| 参数名 | 含义说明 | 是否必须填写 | 其他说明 |
|---|---|---|---|
| 名称 | 任务名称 | 必填 | 名称必须以小写字母数字开头和结尾,名称只能包含小写字母、数字,以及 "-" 和 "." |
| 数据源 | 配置的kafka集群列表 | 必选 | 目前数据源配置需要由后端操作 |
| 入湖数据库 | 写入LakeSoul数据库的名字 | 选填 | 若不填写,按源表所属数据库创建对应的数据库, 若填写,根据填写字段创建数据库 |
| topic名类型 | topic是否是正则 | 必选 | 常规:topic是完整名字,后续可以选多个; 正则:按填写字符串正则一个任务读取多个topic入湖。 注意:若按正则,kafka中数据格式应该一致,即都是avro或者debesium格式的string |
| topic名 | topic名字 | 必填 | 当topic类型是常规时,这里是下拉选项; 当topic类型是正则,这里需填写正则字符串。 |
| kafka数据类型 | topic中数据格式 | 必填 | String:数据格式debesium格式的string; Avro:数据是avro格式,需要配套registry服务。 |
| schema-registry 服务地址 | registry服务 | 当数据类型为avro时必填 | 配置样例:http://ip:8081 (需携带http://) 后续计划配置到数据源信息中之后不用再填写 |
| 数据消费方式 | 消费kafka数据的起始位置 | 必须 | 默认从最新开始消费(如没有实时数据进入,需要选择从最早offset消费) |
| 删除列时lakesoul表行为 | 源表schema删除列时,入湖应对策略 | 保留该列:入湖数据还可以查到删除列,但是schema删除列后,该列数据为null; 删除该列:后续湖里查不到该列数据信息。 | |
| 任务一次消费最大记录数 | 任务一次读取kafka数据条数 | 必填 | 默认值500 |
| source并行度 | Flink source并行度 | 必填 | |
| sink并行度 | Flink sink并行度 | 必填 | |
| checkpoint | Flink checkpoint时间 | 必填 | 默认600000ms,当做一次checkpoint后,入湖数据才会更新查到。 |
| 描述 | 任务信息描述 |
查看详情,编辑,删除,任务启停,查看日志。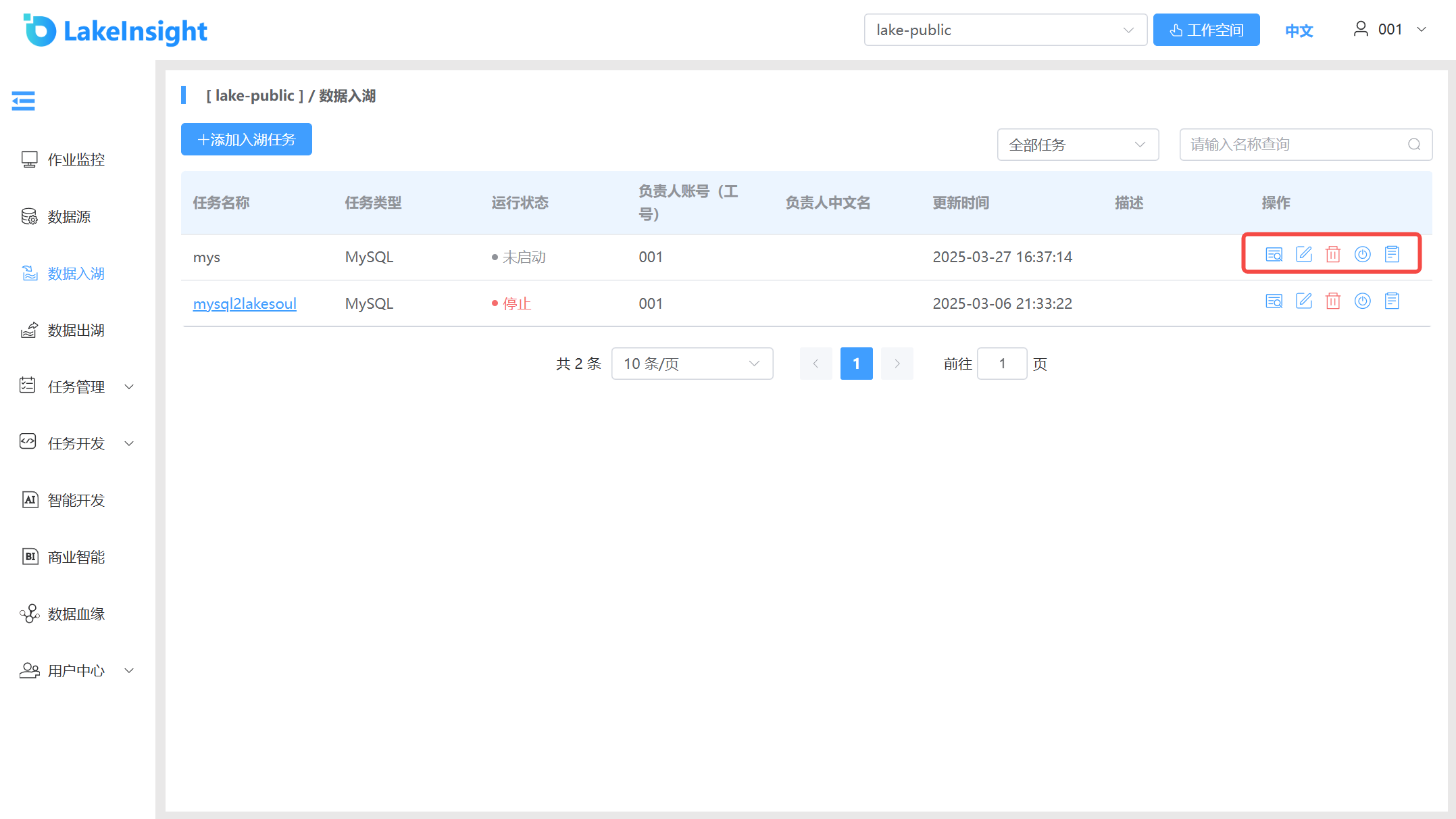
列表中每条入湖任务右侧包含 查看详情,编辑,删除,任务启停,查看日志 按钮,按需操作。